Introduction
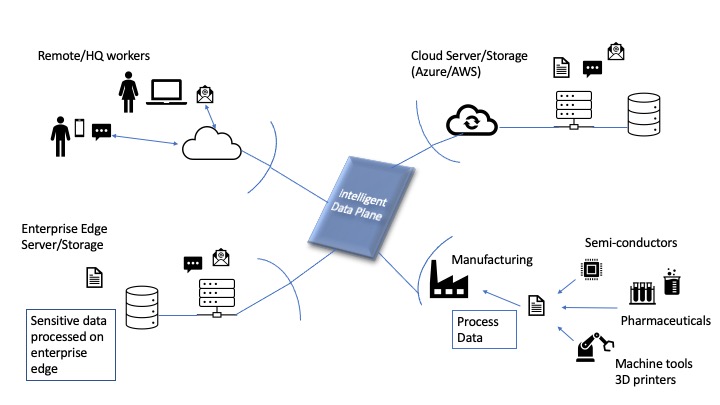
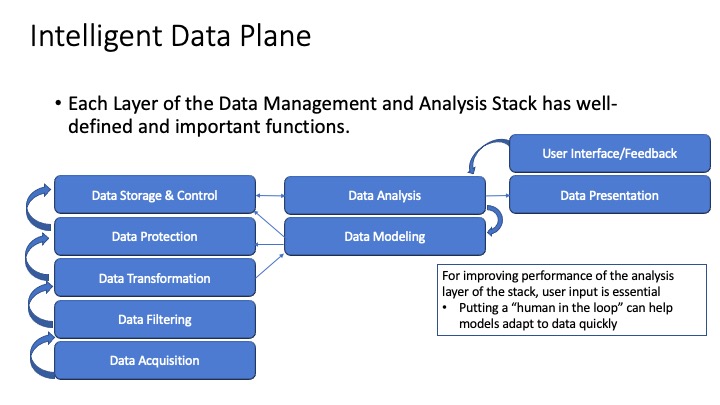
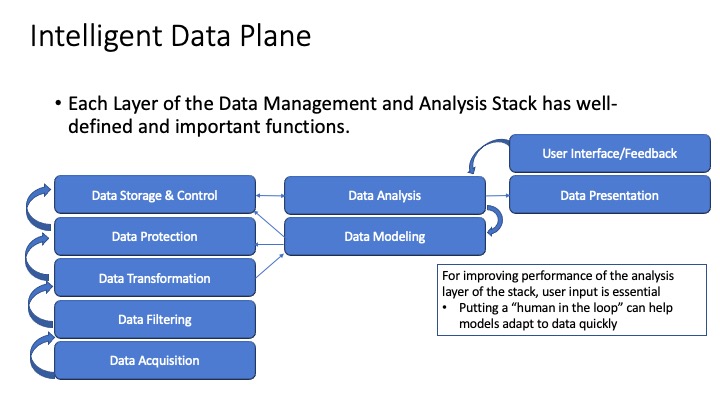
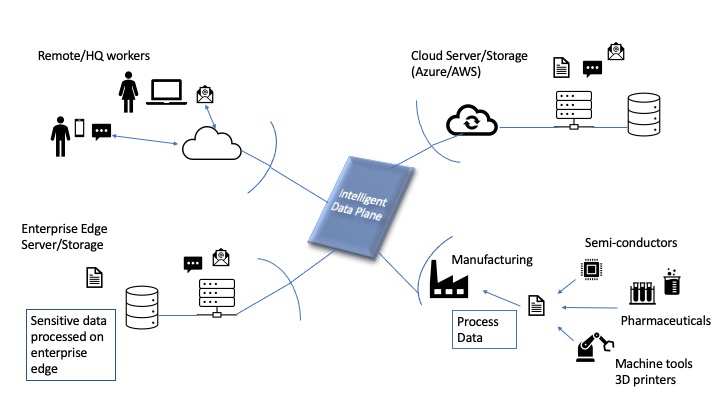
Previously I wrote an article about what I called the “Intelligent Data Plane” where I described how analytic functions and data processing could exist together to allow businesses to make use of their data securely and ubiquitously across departments of an organization. The article described how cloud data platforms have emerged to help enterprises gain insights into the massive amounts of data available to them. I described two new companies, one adding value in the document analysis workflow area (making manual processes more efficient) and one in the manufacturing area (making manufacturing data available to management through analytics and reports) to show the promise of analytic processes in various markets.
In this article I focus on the special requirements within the financial services industry for trade and communications oversight and regulatory reporting. I also highlight how a new company (SteelEye Limited) has built a unique cloud-based platform to serve the needs of this industry and also provide business insight into trade and communications data generally.
Background and Motivation
My experience running the engineering organization that handled communications surveillance and other analytics-based products within Bloomberg LP for five years taught me how critical the analysis of communications and trade data is for financial-services firms. Financial firms (some of the world’s largest banks, hedge funds and private equity entities), rely on 24 hour/day access to the data they generate in their trading and general business operations, the efficient search of these data, and the analysis of their data in relation to financial regulations of all types.
My Intelligent Data Plane article illustrated how cloud-based platforms such as Snowflake Inc. allow companies to harness all of their data into a single view where analytics can be performed. These platforms are great resources for corporations as they allow one “place” where many relevant data sets can be viewed by different departments of the company and then analyzed with Business Intelligence Tools, Data Analytics packages, etc.
Such platforms are fine for general business analysis of data but lack the functionality required for the analysis of financial transactions and the related data in company communications that accompany them. When it comes to the regulatory requirements of financial services firms, specialized platforms are needed.
Financial Service Firms – Special Requirements
The financial services sector is a demanding one. The data that is exchanged to represent transactions and communicate between firms has to be retained (record-keeping) and the data has to be processed and stored in a certain way. Preparing and indexing data for financial services regulatory applications requires special knowledge of the regulations and how regulators, in-house counsel interfacing with regulators and compliance officers need to search and access data. These requirements are more rigorous than those used for general enterprise data (for plain search purposes).
Search criteria around transactional data is important as it is common that the legal and regulatory teams from financial institutions need verification of what is inside their trades, electronic communications and other data, and how these data relate to one another. Data in various formats must be “normalized” so that key data attributes of trades, email and instant message, and even chat room data can be identified with search queries. The time-based nature and custody of communications must be preserved when data is processed for indexing.
These large data sets representing transactions (and communications related to transactions) are often housed within disparate systems that each have a separate search and retrieval interface. It is generally a nightmare to try and coalesce a single view of all relevant data pertinent to a regulatory matter across these enterprise systems.
For this monumental task, a special kind of platform is required; one that is tuned for regulatory reporting but also flexible enough to support general views into massive data sets. Such a platform was designed, built and brought to market by a group of seasoned financial services executives. They formed a company, SteelEye, and built a groundbreaking platform. They delivered this platform in a very compressed timeframe by having the correct expertise within the company and starting with a fresh perspective. The SteelEye cloud-based service, leveraging the near infinite processing and storage capability of the cloud, transcends the power and capability of other solutions by orders of magnitude.
Prior to the SteelEye platform, compliance teams would be required to log in to disparate systems, pull results and correlate them by manual means. This is of course a costly alternative to receiving a single view of results from the highly scalable SteelEye platform. SteelEye provides one view into a firm’s data negating the manual processes required by multiple enterprise databases or search indices associated with single-use “silo-based repositories”.
SteelEye – A Unifying Cloud-Based Platform for Analytics and Regulatory Compliance
SteelEye is a compliance technology and data analytics firm that simplifies trade and communications oversight and regulatory reporting through a unique, fully integrated, and cloud-based platform. By connecting large volumes of data from multiple sources, SteelEye enables firms to meet regulatory obligations quickly, efficiently, and accurately. With SteelEye, firms gain full visibility and control of their trading and compliance operations, with cutting-edge analytics that provide timely insights on risks and opportunities.
Founded in 2017, the company is led by Matt Smith (former Chief Information Officer at Noble Group and Senior Product Manager at Bloomberg) and serves clients in the buy and sell-side space across the UK, Europe, and the US. The company has several key case studies and client success stories documented here. A recent and significant funding event has been completed to accelerate growth into the North American Market in 2021.
This quote from the CEO (Matt Smith) encapsulates the vision and mission of the company:
“What makes the SteelEye platform an exciting and cutting-edge solution for financial firms is its ability to simplify key compliance processes by connecting and making sense of large quantities of data that naturally doesn’t fit together. This enables firms to meet multiple regulatory needs using just one platform and truly use their data to uncover new insights.”
Significance of Team
The team at SteelEye have extensive experience in the regulatory and compliance market. As a consequence of this, they understand all regulatory requirements for building world-class compliance products. Beyond that, they fully understand the sheer scale of processing and analytics required within an industry that has to retain and manage 100’s of millions to billions of transactions per day. This uniquely positions the team to understand how to build not only compliance applications but also enterprise scale applications for the general business analysis market. The blend of team members with both compliance/regulatory and technology experience is unique in my experience and sets SteelEye apart from its competitors. The team has built a suite of applications on top of a massively scalable data platform that can provide insight on both risks and opportunities.
Significance of Product
The team at SteelEye recognized that their market requires a true “Intelligent Data Platform”. The team have extensive experience in the various regulations to which their clients must adhere and have decades of combined experience that shines through in the platform’s applications and interfaces, which help with both financial compliance and business operations management. The applications built on top of the SteelEye data platform provide the support that compliance officers require and that are not available in general data analysis platforms. SteelEye applications leverage the same underlying data set representations for a variety of purposes.
SteelEye have produced reporting applications and an API that allow their clients to get the answers they need for regulators in record-breaking amounts of time.
Matt and I both worked together at Bloomberg LP, so I was not surprised when he showed me the platform and it was designed brilliantly. The user interface leads the seasoned professional or the novice compliance analyst through the process of finding relevant data for reporting or analysis purposes. The value of having all of a firm’s trade and communications data in one cloud platform where it can be analyzed against the requirements of a number of different regulations was evident in a quick demonstration.
Platform Capabilities
- Data Platform
- Record keeping
- Trade Reconstruction
- eDiscovery
- Trade Oversight
- Trade Surveillance
- Holistic Surveillance
- Best Execution and TCA
- Communications Oversight
- Communications Surveillance
- Regulatory Reporting
- MIFID II
- EMIR
- “Insights” – next generation reporting tools
- API
- SDK
Regulatory Support
The SteelEye platform can support a wide range of regulations and rules, including those imposed by Dodd-Frank, EMIR, MAR, MiFID II, SEC, FINRA and more.
Key Attributes of Platform
- Multiple compliance obligations satisfied through applications on one platform
- Various applications for different regulations are supported on one view of a client’s data
- Multiple data sources collected in the platform are viewed as a whole data set
- All applications work on the data set in its entirety
- Each application is tuned by subject matter regulatory experts
- Various applications for different regulations are supported on one view of a client’s data
- Solutions are built to evolve
- As regulations change, the platform is powerful and can adapt to these shifts
- Applications are not constrained by capabilities of the platform
- Automation enabled through Machine Learning (ML) and Advanced Analytics
- to simplify processes, improve investigations and make better predictions
Flexible Platform Adds Value to and Beyond Compliance
Despite having vertical applications that support specific requirements of specific regulations, the platform also supports “ad hoc” analysis of data. Therefore, as regulators or business analysts need answers to questions that are not in a pure regulatory context, the platform can supply the answers.
Technology
The engineering team at SteelEye selected the Elastic Search technology stack (sometimes referred to as and “ELK” stack) as a base for their platform’s analytic capabilities. This was an excellent choice as Elastic Search has petabyte scale, is very extensible and presents API’s to allow for easy integration.
Having led the team at Bloomberg LP that rebuilt its entire data processing pipeline for compliance/surveillance, I respect a team that selects the right technology for not just solving the problems of the present, but also looking to the future and anticipating the need to extend the platform as the needs of customers evolve.
The Elastic Search stack provides:
- Petabyte scale
- Data sharing – REST APIs are built into Elastic Search
- Flexibility – adding documents to the stack enhances the data model naturally as documents (data representations) are stored as vector representations that are the basis for ML models
As mentioned above, the SteelEye platform has tuned applications for specific regulatory adherence but is also extensible enough to handle more “ad hoc” uses that transcend compliance alone. Also (as pointed out above) the platform can evolve to meet new regulatory requirements. SteelEye engineers leverage ML and advanced analytics within the platform for a variety of purposes.
The technology team anticipated the future needs of the platform by utilizing both ML and Classification capabilities into the product. This article explains how the Elastic Search stack can be used for classification of data. Data classification is also used (particularly within Trade and Communications Surveillance) to reduce the occurrence of false positive results and make surveillance alerts more relevant. Examples of how SteelEye has implemented practical items that make surveillance and search results more relevant include:
- Email classification to eliminate non-relevant emails (such as those containing commercial advertising and solicitation emails not related to business operations). Customers can exclude such email messages from being monitored in market abuse watches, and the system “learns” what these “look like” over time – getting better at identifying and excluding them.
- Customers can select the areas of certain communications they wish to monitor, for example the email subject and body, which contain the most relevant content, and exclude sections like the email signature or “the rest of the thread”.
- The surveillance system of the product includes both rules-based (lexicon based) criteria (as is customary and required in many financial services contexts). The lexicon constructed by SteelEye is reported to be many times larger than competitive rule sets. This multi-layered approach (of employing ML plus required rule sets) is very intelligent and again is designed to reduce the number of false positive results reported by the system.
Examples of how the technology team have implemented practical items that make surveillance and search results more relevant include:
- Email classification to eliminate non-relevant emails (such as those containing commercial advertising and solicitation emails not related to business operations). Customers can exclude such email messages from being monitored in market abuse watches, and the system “learns” what these “look like” over time – getting better at identifying and excluding them.
- Customers can select the areas of certain communications they wish to monitor, for example the email subject and body, which contain the most relevant content, and exclude sections like the email signature or “the rest of the thread”.
- The surveillance system of the product includes both rules-based (lexicon based) criteria (as is customary and required in many financial services contexts). The lexicon constructed by SteelEye is reported to be many times larger than competitive rule sets. This multi-layered approach (of employing ML plus required rule sets) is very intelligent and again is designed to reduce the number of false positive results reported by the system.
Conclusion
SteelEye has built an outstanding and award-winning data analysis platform that supports compliance and regulatory reporting superbly. The product is vastly scalable and extensible to support evolving regulations. The seasoned team at SteelEye envisioned the product from a true cloud-based perspective. In so doing, the platform is also extremely useful for general business analytic purposes that can aid commercial efforts of all kinds within an enterprise.