Executive Overview
The data analytics platform revolution is in Stage One of its development. Investors, entrepreneurs and enlightened customers have enabled the development of great platforms that perform data analysis, yield insights on data sets at great scale and deliver enormous value. The term “Artificial Intelligence” (AI) is used to describe the functions that many of these platforms deliver. The right way to think about this may be that these platforms will first deliver enhanced, human-supervised Machine Learning (ML) rather than true native intelligence, and that argument is made here, but this article is more about describing an “Intelligent Data Plane” architecture.
This architecture will enable these platforms to not only ingest data and perform a “best in breed” function based on AI/ML, but to allow customers to hook new platforms together with existing ones in a “data pipeline” fashion where data can move between platforms and add value across all of them. Stage Two of this revolution is building service platforms in a way that allows these “best of breed” technologies to securely share and analyze data among one another and provide greater advantage than they could by working alone.
Background and Perspective
In April of 2012, famous investor Ann Winblad pronounced that “Data is the new oil” on a segment of CNBC. This was a long time ago, but it has proven to be true. In a more recent article (from March 23, 2020), Peter Wagner, founder of Wing.vc, a Silicon Valley venture firm, outlined the importance of data and analytics and what he calls Artificial Intelligence to the modern enterprise.
Peter’s article is an intelligent overview of some companies that he identifies as playing a major role in providing the data intelligence that will give the modern enterprise competitive advantage. He makes some insightful comments about how enterprises will use Artificial Intelligence and Machine Learning to build this advantage.
In the article Peter illustrates how workers in the modern enterprise connect to and utilize data in many different applications or platforms. The nature of the distributed enterprise and the distributed nature of enterprise data is illustrated very well. The number of applications shown in the article also illustrates that data can be used in a variety of ways and across applications. The distributed nature of applications and how the data they use resides in multiple locations and multiple clouds is obvious to the reader. Peter did an excellent job showcasing the landscape of Artificial Intelligence technology, platforms and how they will be used commonly in the future.
Pondering this new “fact of life” it occurred to me that in speaking about analytics, artificial intelligence and machine learning, some of the aspects of how to make data useful get lost in the discussion. For example, making data available to a number of applications and securing it in transit as the data changes locations is now important. Ensuring that the data is in a format that can be consumed by multiple applications while maintaining security of the contents and ensuring only authorized access to the data must also be a consideration. In the past (and in many non-cloud environments) this was not the case. Now such considerations are common business requirements.
Stage One – A Good Start
In actual practice though, I think that the evolution of the data analytics “industry” is in stage one of its development. There are great platforms and services that have been built, but the second stage of industry evolution will be when we can use platforms seamlessly across data sets, transforming the data as necessary to allow the “best of breed” applications to work together. In actual practice, most enterprise applications rely on their own databases and access paradigm. Data is not universally useful and fungible across different platforms.
When a manager in Human Resource Management can access data selected (and made anonymous) from the communications sent within the company (without a manual step being necessary to make the data anonymous) to run analysis that will indicate workplace satisfaction trends, we will have begun to make use of data. We of course have to ensure the platform will maintain the security of the data and anonymity of the senders but this would be a great benefit to help management understand what to improve about the workplace environment.
Like oil, data has to be extracted from its source, refined, moved to where it is useful, and used in a productive way. It has to be protected while it is stored and there are regulations for how it can be stored as well. So in a lot of ways, data is like oil in that it is powerful and precious and requires special handling to be useful.
Given these facts, it occurred to me that there is an emerging model for how to think about data and data analysis technology. As the networking world defined the seven layer “OSI model” of how network technology is divided into layers of functionality, there is a similar (but different) model emerging for evaluating data handling and analysis software. I have named this model the “Intelligent Data Plane” and compare it in some ways to the OSI Seven Layer stack defined for networking.
The Intelligent Data Plane
A new “Intelligent Data Plane” is necessary to connect and identify all the data moving through an enterprise and help prioritize and manage it. Data from users, manufacturing locations, supply chain partners and cloud services must be accounted for in the Intelligent Data Plane. This intelligent layer of SW is illustrated in the following diagram:
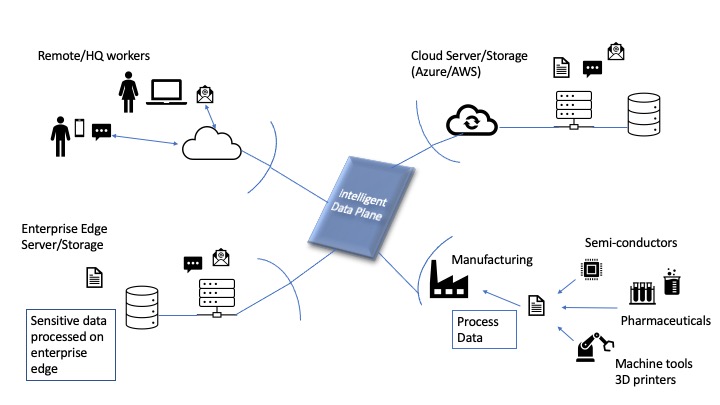
At a high level of abstraction it is important to visualize that the modern enterprise is distributed and data comes from many different applications. Data is sent from different users and is often stored in diverse systems at multiple locations. Given what is in the data itself, who produced it and where it originated, the data will have certain value and will require certain types of handling. Data should reside and be processed in either the “cloud”, “hybrid edge”, “edge computing”, or pure on-premise locations, depending on the security and processing requirements of data items.
A set of components implementing the “Intelligent Data Plane” of a processing stack provide the necessary identification, indexing, labeling, encryption and authorization functions to protect and use data in a cross-platform, multi-user environment.
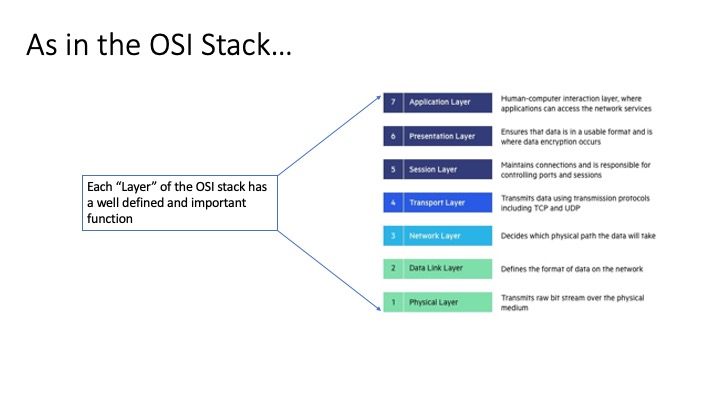
OSI Stack for Networking
The following diagram illustrates how the OSI stack for networking delineates the required functions to supply services from applications running on a TCP/IP “stack”.
Intelligent Data Plane (Functional View) “Stack” Components
The Intelligent Data Plane, in a way somewhat analogous to the OSI model for networking, has defined functions. The functions work together as data passes through this “data analysis stack” to provide data that is valuable to users through applications. Such a stack can work together as a pipeline to provide data that can be useful and securely available to given sets of users and applications. The stack enables users to “interact” with the data and analysis algorithms to refine the classification capabilities of the software.
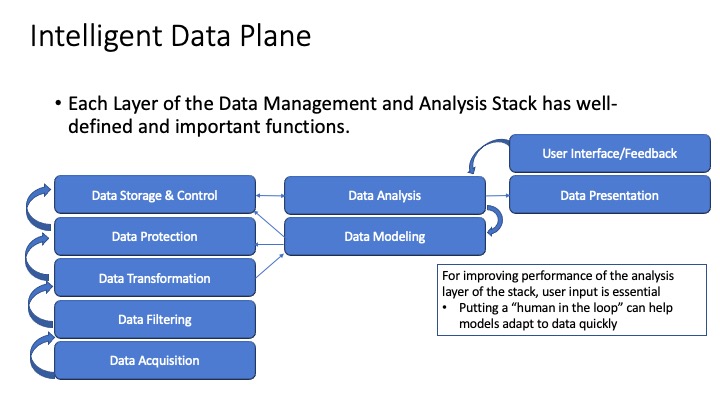
All of these components need to be present to capture, filter and safely store data that can be analyzed and used. As with the OSI layers of a networking stack, each layer of the Data Analysis stack has to perform its function to make the data relevant, meaningful and secure.
Stage Two – Extending Capability
Note that data can move through the components of such a data plane, or processing stack in pipeline fashion, adding value to data items as they are processed by applications. Stage two of the data revolution will be achieved when applications can use components implementing these functions as they need them. This will allow an application to be built quickly, utilizing whatever components of the intelligent stack are required for processing and analyzing then presenting data of interest to users.
The Intelligent Data Plane is software that provides the functions of:
–Intelligent data acquisition (source-specific connection and object/attribute filtering of data). Examples would be reading files from a specific Amazon S3 bucket or receiving emails from a certain mailbox location where customer inquiries are stored. This is largely present in Stage One platforms and is mentioned here for completeness.
–Filtering rules/initial analysis to collect only relevant data. Examples of this would be collecting files that have been stored within a specific timeframe, or emails that are sent to a specific mailbox address, or retrieving database records with a certain range of identifiers in a certain column of a table. These functions may not be as “automatic” as they need to be in today’s stage one environment.
–Data Transformation into objects that support analytics. An example would be parsing a PDF file and determining if it has a table, the table within the PDF has data with certain values, and transforming the data into a JSON object (document) and storing those objects for further analysis by another component within the Data Intelligence stack. Stage two platforms will provide standard mechanisms to normalize and share data among applications/platforms.
–Movement of data to third-party modeling and analysis software or modeling software within the intelligent data stack itself. Identifying data with sensitive personally identifiable information (PII) and labeling the data so that these data items can be protected. Movement of data and classification and labels (while maintaining user context of who defined the labels) is largely platform specific in stage one products. Stage two would make these a universal attribute of data analysis systems.
–Data Protection (encryption, obfuscation). Examples would be encrypting objects or documents that have sensitive data. Stage two would make the encryption and key management transparent to users, and encryption/data protection a user-centric or community centric attribute of classified data sets.
–Data Analysis/Classification – with “human in the loop” capability to aid and improve classification performance over time. Examples would be a user interface and data presentation layer that allow a user to reclassify data that the classifier has mis-labeled. Such data would be reintroduced to the training SW to allow the model to be updated and allow the classifier to work more accurately in subsequent classification runs. Stage two would evolve to include this as base functionality. Stage one products add this today platform by platform at the application level.
–Data Storage and Control (storage plus indexing for eventual retrieval). Examples would be functionality to index data items, store data items and labels such that documents can be searched and retrieved by either keyword attributes of the documents, or classification labels associated with given data items. Most Stage one platforms have this today, or provide on-demand indexing based on meta data attributes for deeper content searching. Stage two platforms would enable association of user-defined labels with certain sets of data items and allow them to be searched along with strict data attributes.
–Data Presentation and User Interface Layers for Viewing Data and the results of classifications.
The Data Presentation layer must be backed by APIs and technology that can store the labels for multiple classifications and present them in the proper context for a given user. All documents that are classified accurately and given a specific label should be able to be associated and presented to the user who has the authorization to view them.
Summary
The Intelligent Data Plane is a reference architecture defining layers of functional components that aid the analysis and management of data in service platforms. The evolution from stage one platforms that provide great value but that may not be built with all of these functions was explained. The different layers of the architecture were presented to allow the reader to understand what functions can be built to extend the platforms that exist today.
The ability of the architecture to supply “pipelined” processing flows that allow multiple platforms to securely share data and provide their own best of breed functionality into a greater benefit for customers is the end goal of such an architecture.